技术琐话
日常的工作学习中,经常会看到好的知识点,对自己有提示的一句话,或者是自己突然想通了一件事情。这里以“技术琐话”作为主题来聚合。
2024.04.12
- road.sh: 一个不错的站点,涵盖了基本所有研发岗位的成长路线图。
2024.02.29
- 看了阿里这几天很火的Emote Portrait Alive项目,发现又是演示demo+论文+README,这已经成了阿里的开源风格了[笑cry] 这个项目的平替其实有不少:DreamTalk、SadTalker、Wav2Lip。商业化的类似的也有d-id、heygen等。
2023.11.29
- 看到一个类比把大语言模型类比成程序数据库,那么提示词就是程序索引+程序输入,好像还真是这么回事
2023.10.21
- 耗费了大量精力调优提示词,最后发现效果提升很少。目前的认知就是在做AI伴侣这一块,提示词微调能带来的效果很一般,实在不如做一些工程上的优化好。
2022.07.22
- 凡是被很多人或者自己许多次重复的好习惯,都要将其自动化,绑定到工具之中,以"Don’t make me think"的方式来推广最佳实践。
- 研发体系支撑价值驱动的业务创新里讲的XasCode,和我之前看过的”Code is Law“本质是一样的。研发体系中,能够通过Code解决的问题都能够实现比人与人传播更好的保证下限的效果,并且一定程度上是可以提高效率的。比如打包过程的口口相传转变为脚本化、平台化获得地质量和效率提升都是显而易见的。
2022.06.07
技术如何共享核心的财务KPI?


2022.06.06
从职能管理到业务管理,这是一个非常大的跨越。哪怕你是一个非常有经验的职能管理者,管过几千人的团队,也不意味着你就可以顺理成章地孵化出一个5个人的独立业务,二者的能力要求完全不一样。【from 前美团COO干嘉伟】
高级管理者解决价值问题,初中级管理者解决效率问题,一切取决于个人定位。【from 乔新亮的CTO复盘课】
- 解决效率问题依赖专注做事的习惯和方法、高效的时间管理方法和「别让猴子爬上背」的管理价值观;
- 解决价值问题依赖产品型研发组织的构建、对 CEO 的影响力以及对业务及其他部门的影响力。
2020.07.09
- 自己在梳理一些知识的时候,一般都是按照what、why、how三步走。看到也有人会按照why、what、how的顺序。在明确学习某个事物的时候先搞明白这是什么,再去探索为什么会有这个事物;在不知道是具体的某个事物只是在寻找方案的时候,则是需要先搞明白为什么要做这件事,再去找到这件事到底指的什么。
2020.02.17
有脾气是本性,能够控制脾气才是本事。
所有的知识都要追溯至第一手资料以保证其权威性。
知识点串成知识线,知识线连成面,面再成体,进一步形成知识体系。
软件开发时,对于时效性、稳定性、效率与可维护性、可使用性、开发友好性的取舍,往往会注重前者。
逻辑是道,方法论是术。
架构的道与术:架构思想是道,技术框架是术;架构原则是道,架构技巧是术。
做代码审查时,着重审查结构,不要太重视语法细节。
信息技术层面的三个引擎:计算能力/CPU;存储能力;网络带宽。
Continuous Delivery doesn’t mean every change is deployed to production ASAP.It means every change is proven to be deployable at any time. –Carl Caum。持续交付是指每次的变更都不影响随时将系统部署。
【如何排查问题】在排查问题时,不要第一时间就怀疑是第三方(SDK、库、服务)的问题。实践证明,绝大多时候不会是这方面的问题。
【获取知识不能太功利】 面对新事物,先接纳,再判断。不要轻易就否定,即使经过自己的思考后确实没啥价值,这期间的思考过程也是一种知识梳理和思维锻炼。
【如何做决策】当品质比成员接受程度高时,独断式决策;当接受程度比品质重要时,群体决策(共识);品质和接受程度都高时,咨询式决策;品质和成员接受程度都不高时,哪个方便选择哪个。(很多书和文章都在讲“共同决策”的好处,但群体决策一般来说不会是最好的决策,而是风险相对小的决策)
【云计算服务如何选择?】初创公司在业务刚起步时,使用SaaS或者PaaS快速开发业务;业务成长到一定规模之后,再逐步转移到IaaS或者私有云降低成本。
2019.07.18
看到耗子大神的博客上的这篇文章: Cuckoo Filter:设计与实现。乍看一下,以为又出了什么nb的大数据查重算法了。看完之后发现作者就没搞清楚bitmap和bloomfilter到底是为了什么场景出现的。
- 在元素能够映射为唯一数字时,大数据查重算法一般会选用bitmap能够尽量少的占用内存,直接将元素映射到bit数组的相应位置上。
- 在元素无法转换为唯一数字时,经常的用法是取其hash值,此时由于有碰撞,经典的hashmap实现是用链表法解决。当接受误差的时候,可以选择bloomfilter能够节省内存占用。
- 文章讲的算法是精确查重,在元素可以对应唯一数字时比bitmap没有任何优势。在元素无法对应唯一数字时,这个对比的应该是hashmap的各种实现。但是本质上你还是要存储这么多元素。这个对比哈希碰撞的经典算法(开放地址法、重hash法、开链法)并没感觉有什么明显优势。
- bitmap、bloomfilter是解决"查元素存不存在",并不具有经典hashmap的"根据key获取value"的功能。虽然后者也能够支持"查元素存不存在"。
最近在做微服务的落地规划时接触到了Cookie cutter scaling这个名词。文章里的说明是相对于单体应用,Cookie cutter scaling的特点就是通过嵌入式lib做组件化,能够便于扩展,从而不引入分布式复杂度就能够承载大流量。但其实现在的单体应用也基本都是这样做的了,并非是Cookie cutter scaling的特点了。不知道是否理解有偏差。Monoliths, Cookie-Cutter or Microservices?、Cookie Cutter Scaling
2018.09.03
推送实现方式:轮训、长连接、长轮训(依赖于异步IO机制,如Java中的异步Servlet)。
喜欢到处听讲座的人通常心态上很好学,但很可能思考不足,所以知识很容易流于表面。喜欢看一本一本书的人不但好学,而且通常比较习惯于深度思考。深度思考,才能具体改变你的知识体系。看书时,可以和作者进入到同一个频率,对文字的内容产生共鸣。 @蔡学镛 so,建议搞技术的同学少参加会议,少混圈子,多看书。
提出问题之前最好先想好自己的答案或者思路,切忌总是吐槽却不去解决问题。
对新技术的调研需要梳理零散的知识点,最终一定要有输出:分享或者文章。
想到一个思路,要深入思考下去,即使表面不可行,也可以使其可行,直至确实不可行,再换思路。
人的时间管理效率会差3倍;注意力管理的效率会差30倍;思考方法学习方法的效率差300倍。so,找到好的学习方法是非常关键的。
一个人有没有计算机思维很大程度决定其在技术上的上限。而我所谓计算机思维即能否用计算机的方式来看待问题、解决问题,能否很好地把现实问题转换为计算机可以理解的问题。这东西一方面靠天赋,一方面靠后天刻意培养。
2018.01.01
你东西学得广了,别人就会攻击你不够深入;你东西学得够深了,别人就会攻击你知识面不广;你专精在技术时,别人就会说你管理不好;你花心力好好做管理之后,别人就会说你技术没有跟上;你研究方法论时,别人就会说你很虚;你专心做项目时,别人就会说你没有提炼方法,没有系统。… 想挑你毛病,总有办法。但你自己知道自己在干什么最重要,那些你的「缺点」其实可能不是缺点,而是一件事物的另一面。你选择这一面,自然会缺另一面。这是取舍点,不是优缺点。(from 微博@蔡学镛)
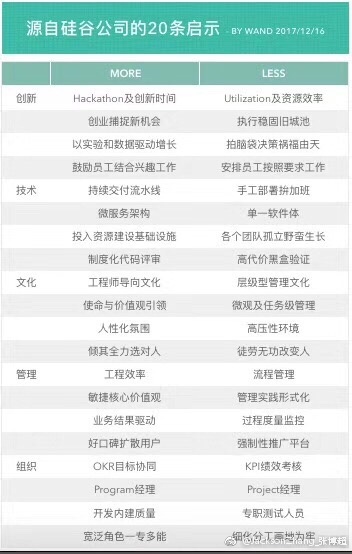
来自硅谷的启示
在写Java代码的时候,如果匿名内部类里面传递变量,变量必须声明为final,而在Java8中,可以不用写这个final了,因为Java8引入了Effectively final 功能,由系统默认添加。What is Effectively Final variable of Java 8
使用maven-javadoc-plugin,突然失败了。。。于是怀疑是代码的问题,然而以前一直是好的。突然想到了会不会是我升级了jdk8造成的问题,万能的google一搜,发现果真是jdk8带来的新特性DocLint引起的问题。对此的解决办法,要么是按照规范好好地写注释,要么可以加入参数-Xdoclint:none。
将Nginx中的一个配置指令proxyinterceptorerrors设置为true,可以捕获后端服务器返回的错误码进行处理,从而可以使用nginx自己的错误显示页面。
在Servlet开发中,request.setCharacterEncoding必须在所有filter最开始执行,否则只要调用过request相关方法去获取其参数等,再去设置编码是无效的。
Servlet3.0引入的异步servlet和connector的NIO是不同的。前者指的是处理业务逻辑的时候的异步,而后者指的是接受连接时候的异步。对于前者,其实最后的业务逻辑还是交给了线程池去处理,不过除此之外,还有一个线程专门做业务调度而已。
Servlet3.1引入的HttpServletRequest.changeSessionId 和HttpSessionIdListener ,主要是为了防止session fixation攻击。那么什么是session fixation攻击呢,简单点说就是一次访问网站的session的id是不会变的, 那么攻击者诱导受害者使用一个确定的session id(攻击者可以先去访问网站获得一个id)去登录某个网站,就可以伪造成你的身份获得各种权限。
Java中File类的listFiles和list方法最终调用的是FileSystem的本地接口,返回的文件列表顺序是没有保证的。Spring中的san某一basepackage下的类就是使用的此方法,因此加载的bean的顺序也是无法保证的。这一点需要特别注意。
大家都知道在Spring中如果想要扩展自己的namespace,需要配置spring.handlers和spring.schemas以及*.xsd文件,从而可以动态生成bean,那么如果抛开xml配置,只使用注解该如何做到添加自定义的注解来生成自己的bean呢?一种方式就是:实现ImportBeanDefinitionRegistrar接口。
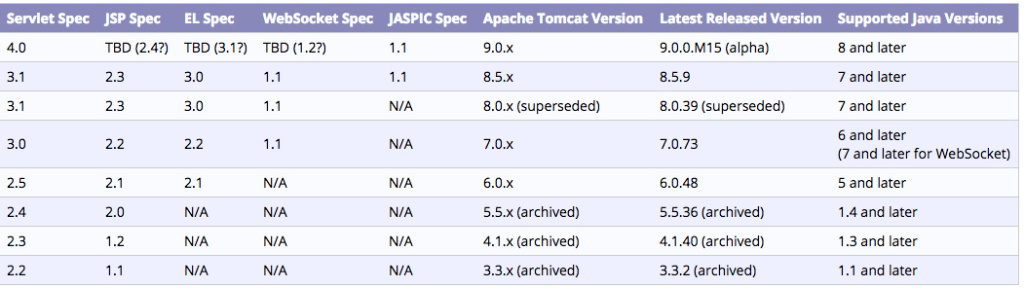
Tomcat各个版本特性对比图
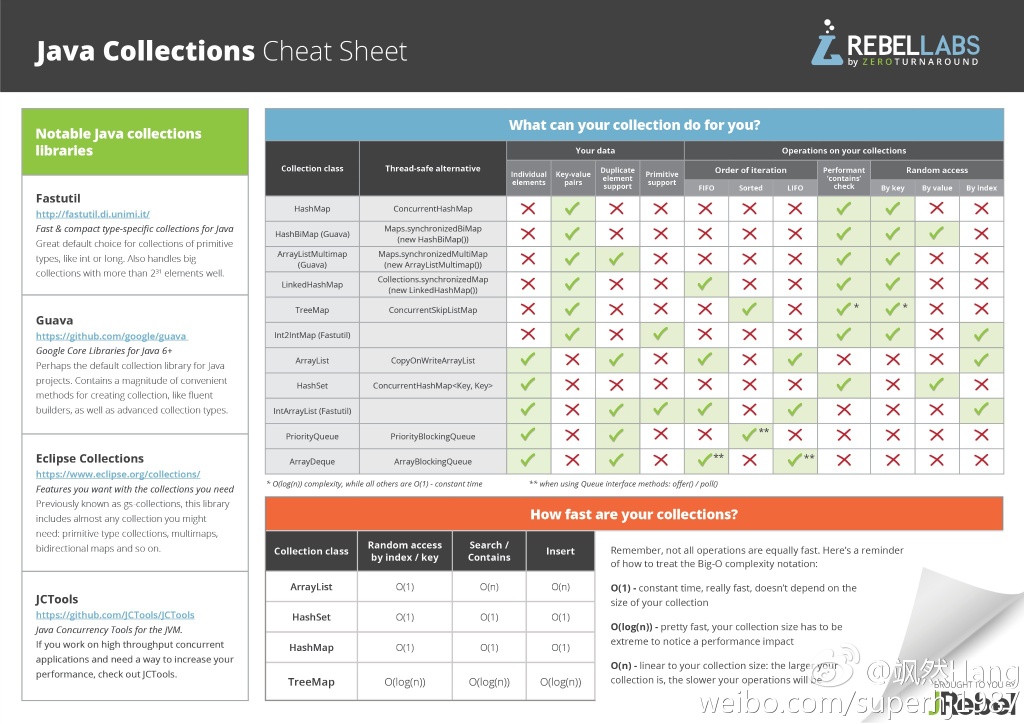
Java集合类对比图表
【学习intellij插件开发有感】为了方便大家的工作,尝试去写intellij插件。从网上找了几个用户比较多的插件的源代码。很多都是gradle做项目构建的。咋一看build.gradle的语法,怎么都无法和以前用过的groovy联系起来。良久才明白,原来gradle用了很多trick。比如创建一个task的同时创建同名的property以及同名方法;大量使用delegate,传递闭包;在没有说明调用对象的情况下,Gradle会自动将调用对象设置成当前Project。
2017.11.25
Java的thread模式其实已经是一种非常好的并发模型了。scala中的akka引入的actor并发模型,虽然从理论上确实是actor,但由于其是用户态的程序,并不能够控制cpu分配,使某些任务让出执行权。这一点上,目前所有号称实现了actor的语言中,只有erlang是完美实现的,其他的都不尽完美。尤其,是jvm上的actor,还是建议大家不要用的好,老老实实用thread去解决并发问题。
【学习intellij插件开发、vuejs有感】阅读各种技术的使用/说明/示例/原理文档时,能不能快速吸收为自己的知识?能不能注意到细节关键点?是一个开发工程师优不优秀,能不能比别人更突出、更快成长起来的一个非常重要的地方。
缓存更新的三种模式:1. Cache Aside Pattern: 应用程序在数据库和缓存之间周旋,以数据库为准。适合一般情况,因此最常用。2.Read/Write Through Pattern: 应用只读写缓存,缓存同步写回数据库(同步是指应用等待着写回完成)。理论性能略高一些。3. Write Behind Caching Pattern: 应用只读写缓存,缓存异步写回数据库(应用不等待写回完成,缓存若宕机将丢数据)。理论性能最高,如果有Write Ahead Logging特性,可避免丢数据,但略为降低性能。
对于一个后端系统,一般来说,提高其响应性能的三板斧:队列(Queue)、缓存(Cache)和分区(Sharding)。队列可以缓解并发写操作的压力,提高系统伸缩性,同时也是异步化系统的最常见实现手段;从文件系统到数据库再到内存的各级缓存模块,解决了数据就近读取的需求;分区保证了系统规模扩张和长期数据积累时,频繁操作的数据集规模在合理范围。
分布式系统的3c指的是:共识(consensus,为了避免脑裂问题)、并发(concurrency)、一致性(consistency)。这个可以联想到分布式系统的特性的cap,不同的是3c是可以都满足的,而cap在大多数情况下是以牺牲某些特性来做为代价的。
谈到函数式编程总是逃不开Monad这个概念的。Monad就是一种设计模式,表示将一个运算过程,通过函数拆解成互相连接的多个步骤。你只要提供下一步运算所需的函数,整个运算就会自动进行下去。
The interesting thing about performance is that if you analyze most programs, you find that they waste most of their time in a small fraction of code. If you optimize all the code equally, you end up with 90 percent of the optimizations wasted, because you are optimizing code that isn’t run much. The time spent making the program fast, the time lost because of lack of clarity, is all wasted time.《重构》一书的一段话,也是不要过早优化的意思,即在不确定这段代码真的会被频繁调用、真的是系统的性能瓶颈之前,没必要花时间优化此处的性能。
这句话揭示了成为技术专家的一个关键特质: 理解一个系统应该如何工作并不能使人成为专家,只能靠调查系统为何不能正常工作才行。(From SRE ,by Brian Redman)
技术书籍的出版门槛越来越低,该如何识别是否是一本烂书呢?在我自己看来,英文书籍质量远远好于中文书籍,翻译的版本一般来说质量也不错,不过作为一个互联网从业的技术人员,能够直接阅读英文原版是最好不过的。而对于中文书籍,如果是以公司名义或者书的序多于3篇,是一本烂书的概率非常大,写推荐语、写序的人名头越大,并不代表这本书的质量有多好。此外,现在某sdn专家真的是门槛低到不行,挂这个名头出的书更要慎重选择。对于InfoQ推荐的书,倒是可以值得一读。